BNL 缓冲区初始化代码分析
BNL 是 Block Nested Loop 的缩写,表示 基于块的嵌套循环连接,是 MySQL 优化连接查询的一种方式
BNL 缓冲区的初始化,是执行连接过程中使用连接缓冲区的基础,本文会详细分析 JOIN_CACHE_BNL::init() 方法及其调用的其它用于初始化的相关方法
BNL 缓冲区初始化流程主要涉及方法,以及调用关系如下图:
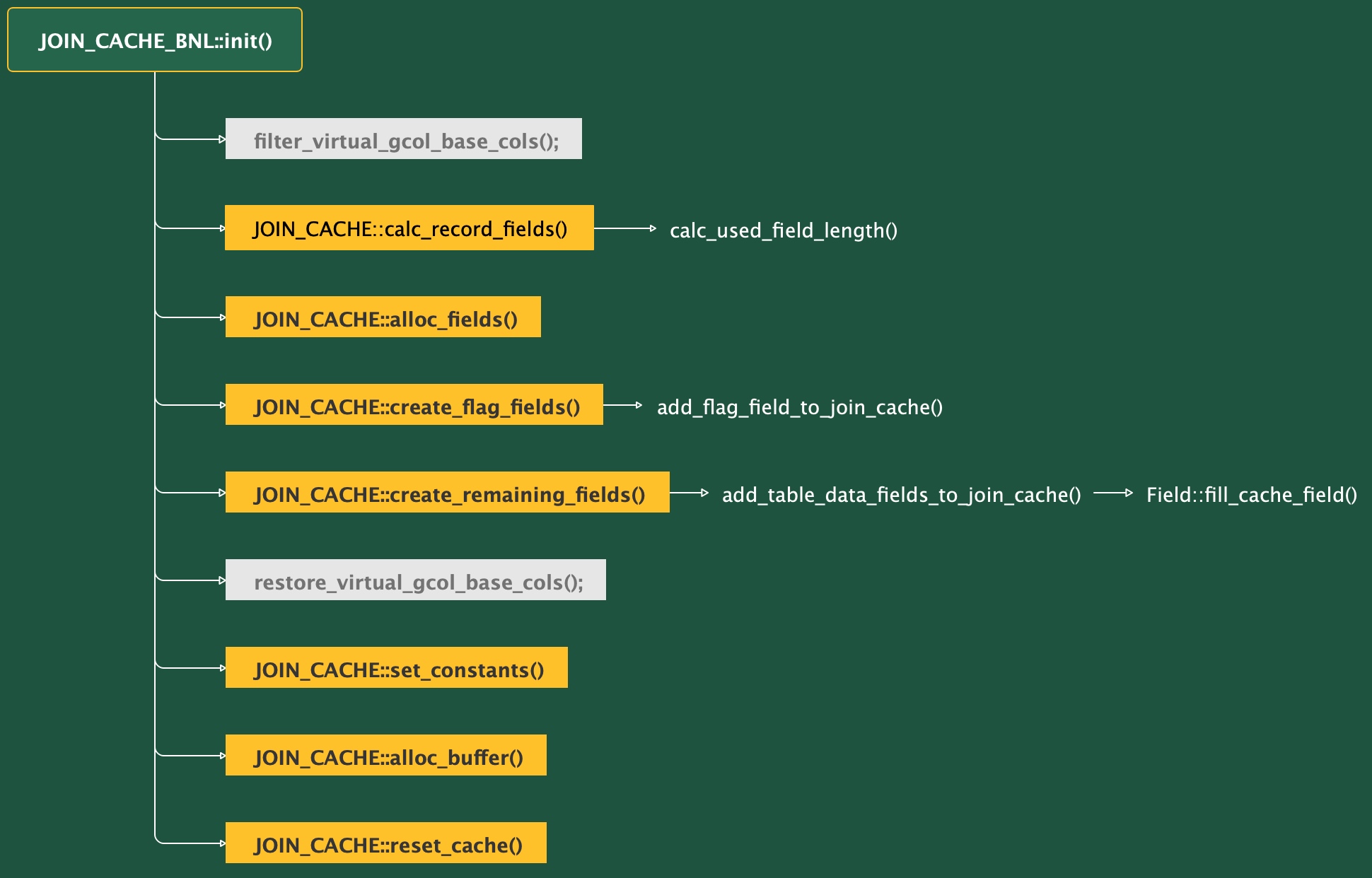
Tips:本文基于 MySQL 5.7.35 版本源代码
1. JOIN_CACHE_BNL::init()
1.1 主要实现功能
init() 方法在实例化 JOIN_CACHE_BNL 类之后调用,用于初始化连接缓冲区的结构
从表中读取的记录的每个字段是以 CACHE_FIELD 结构体的方式存储连接缓冲区的,CACHE_FIELD 在源代码中被称为 字段描述符
本方法的主要功能就是调用其它方法为 连接缓冲区 及 字段描述符 分配内存,以及预先计算一些在后面执行连接查询的过程需要使用的数值
1.2 代码分析
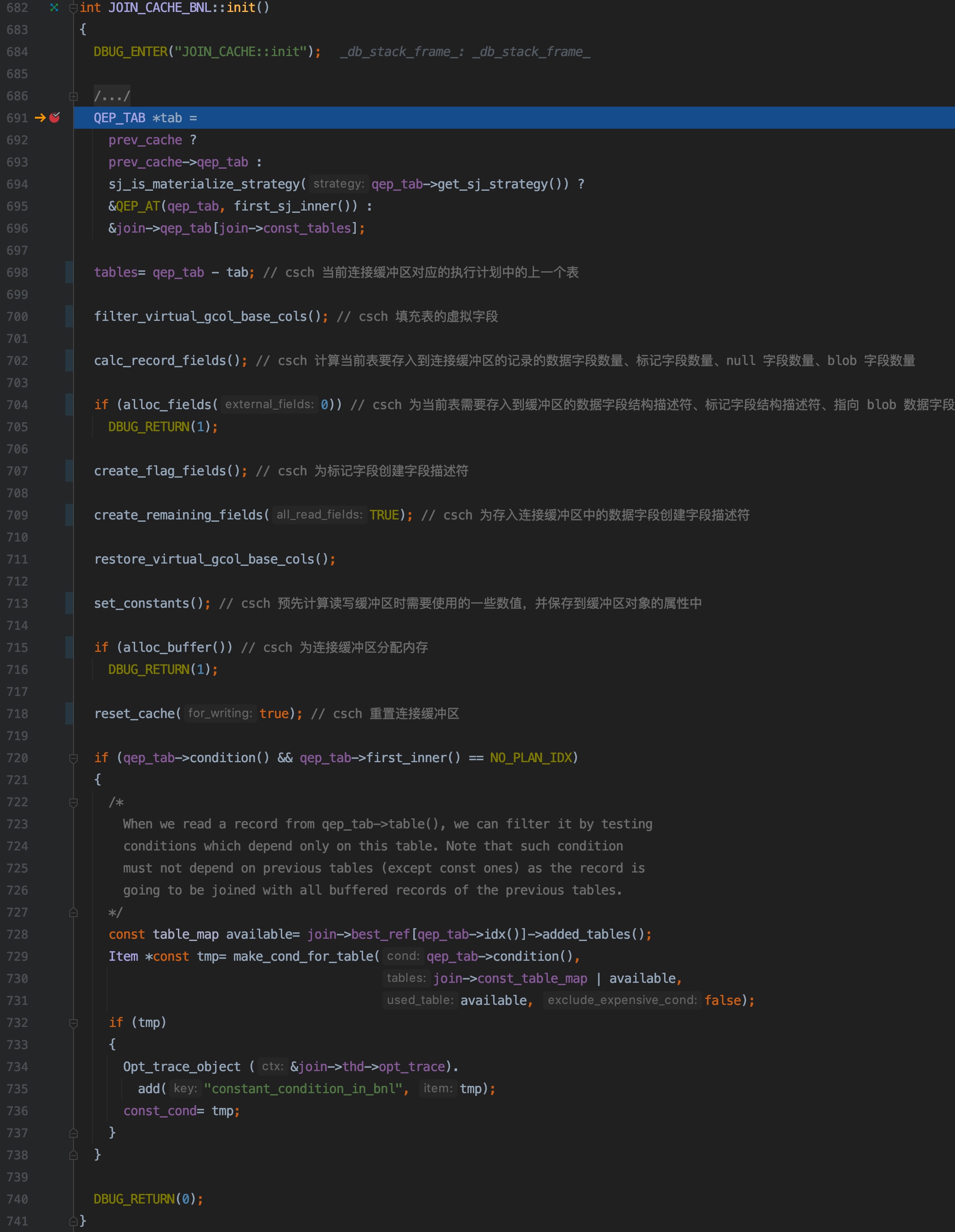
691 行,判断当前初始化的缓冲区是否有前驱缓冲区,如果有,则使用前置缓冲区的对应的表的信息来初始化当前缓冲区
694 行,判断 qep_tab 对应的表是对子查询使用半连接进行优化,并且优化策略使用的是物化表,则使用半连接的第 1 个内表的信息来初始化当前缓冲区,否则使用执行计划中的第 1 个非常数表的信息来优化当前缓冲区
常数表,指的表中没有记录、只有 1 条记录,或者是通过 WHERE 条件只能查出一条记录,在查询优化阶段,就会读取该表的记录,并把 SELECT 语句中该表对应的字段都替换为实际的值,在执行阶段,就不需要再去读取该表了,SELECT 语句中这样的表就是常数表 SELECT 语句中不是常数表的那些表,就是
非常数表了
691 ~ 696 行,是为了找到查询执行计划中,在 qep_tab 对应表之前执行的查询的表的信息来初始化 qep_tab 表对应的连接缓冲区,为什么要这么干呢?接下来用一个例子来说明
1SELECT t3.*, t4.*
2FROM t3 INNER JOIN t4 ON t3.i1 = t4.i1
3INNER JOIN t1 ON t1.i1 = t4.str1
4INNER JOIN t5 ON t5.i2 = t4.str1
5WHERE t3.i2 > 100 AND t4.str1 > '600'
上面的示例 SQL,执行计划如下:


从上面两张图中可见,执行计划中各表的执行顺序为:t1、t5、t4、t3,而在 t5、t4、t3 三个表上都有连接缓冲区,都使用了连接缓冲区来提升连接查询的性能
对于 t5 表的缓冲区来说,是要把 t1 表中的符合 WHERE 条件的记录查询出来,存入 t5 表连接缓冲区,等缓冲区满后,一条一条的读取 t5 表中符合条件的记录,来和缓冲区中每条 t1 表的记录进行比较,判断是否能够匹配(在上面示例中,t1 表和 t5 表之间没有连接条件,所以认为 t5 表中读出来的记录和缓冲区中每条 t1 表的记录都是匹配的)
对于 t4 表的缓冲区来说,是要把 t5 表中符合 WHERE 条件的记录查询出来,存入 t4 表连接缓冲区,等缓冲区满后,一条一条的读取 t4 表中符合条件的记录,来和缓冲区中每条 t5 表的记录进行比较,判断是否能够匹配
对于 t3 表的缓冲来说,t4 表中的记录和 t3 表中记录的匹配逻辑,同前面的描述是一样的
700 ~ 718 行,都是调用其它方法执行相应的操作,会在后面的小节中详细介绍
700 行,调用 filter_virtual_gcol_base_cols();711 行,调用 restore_virtual_gcol_base_cols() 都是处理虚拟字段的相关的逻辑,本文中暂不介绍
720 ~ 738 行,把 WHERE 条件中关联了当前表和常数表的连接条件找出来,赋值给 JOIN_CACHE_BNL::const_equal 属性,在后面执行连接操作的过程中,会先判断从当前表读取出来的记录,是否和满足这些条件,如果不满足,就直接跳过,如果满足,才会把该记录和当前表的连接缓冲区中的前一个表的每条记录进行匹配,这样就能减少一些不必要的判断当前表的记录和前一个表的记录进行匹配的工作量,达到提升性能的目的,所以 JOIN_CACHE_BNL::const_equal 是个很重要的属性
2. JOIN_CACHE::calc_record_fields()
2.1 主要实现功能
该方法的主要功能是计算连接执行过程中需要使用的 4 个数值,并把计算结果保存到连接缓冲区对象的 4 个属性中:
flags_fields:标记字段的数量fields:标记字段数量 + 数据字段数量blobs:blob 字段的数量(blob 字段也是数据字段,至于为什么要单独记录 blob 字段数量后面会说明)with_match_flag:对于外连接的第一个内表、用于标识表中的记录是否能够匹配外连接的外表的记录;子查询使用首次匹配半连接优化方式时,用于标识当前从半连接的第一个内表读取的记录,对应的驱动表的记录是否已经被加入到结果集中了
存入连接缓冲区中的字段有两种类型:标记字段、数据字段,在后面其它方法的分析过程中会有详细的说明
2.2 代码分析
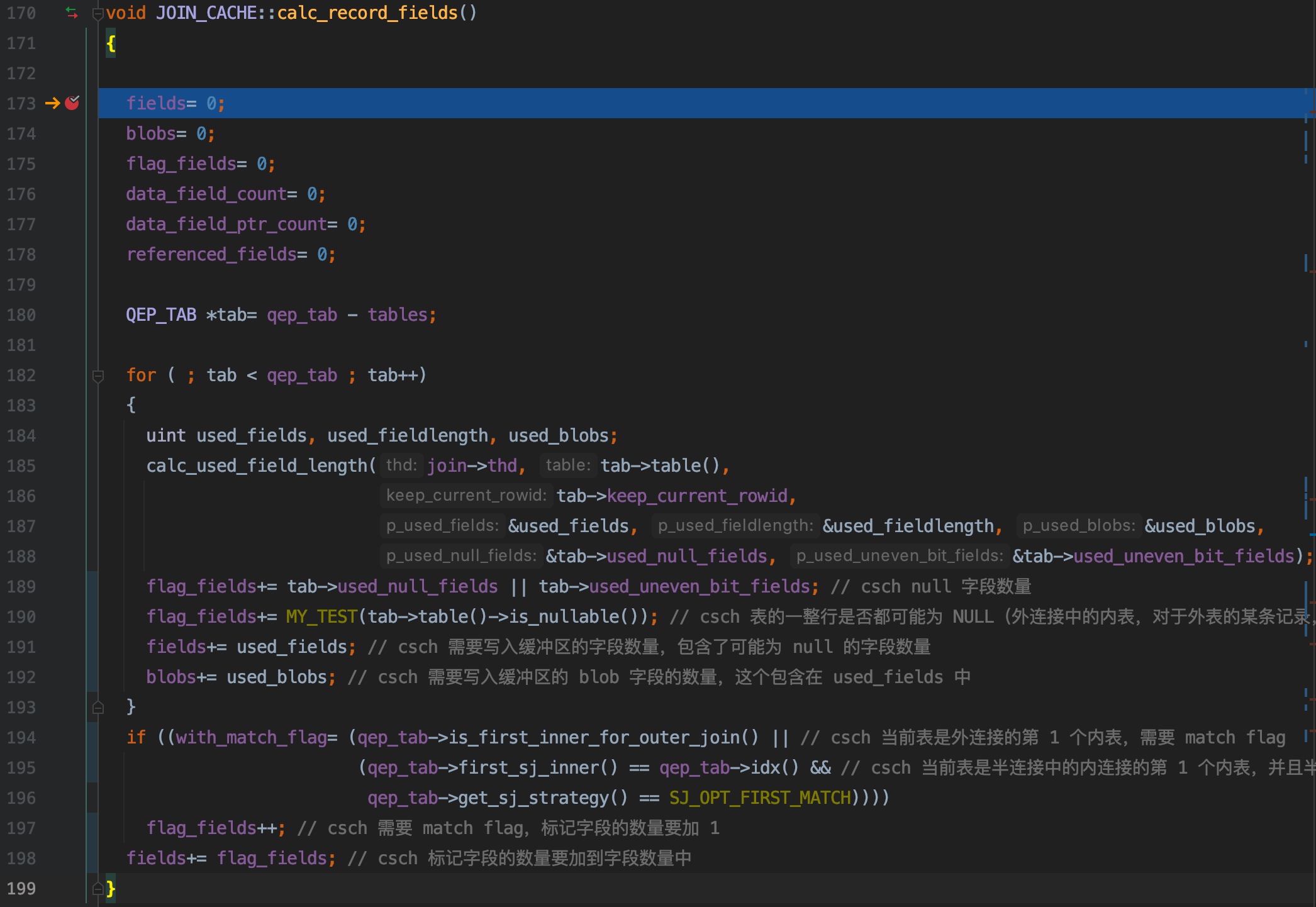
189 行,如果表中存在可能为 NULL 的字段(建表时,字段没有指定 NOT NULL),或者表中有 BIT 类型的字段,且 BIT 类型的字段位数不是 8 的整数倍的时候,字段内容中对应 位数 % 8 的那些高位,会存储到行开头的 NULL 区域,例如:status bit(19) comment '状态',该字段类型有 19 位,19 % 8 = 3,那么 status 字段的高 3 位会存储到行开头的 NULL 区域(这里指的是 MySQL 的 server 层的行格式,和存储引擎无关,关于 BIT 类型字段更详细的分析,后面写了相关文章之后再把链接放到这里)
如果存在上面 2 种情况,flag_fields 的值会加 1(因为 tab->used_null_fields 和 tab->used_uneven_bit_fields 都是 bool 类型的变量,如果其中有一个值为 true,转换为整数就是 1),表示需要一个标记字段用来标记存入到缓冲区中的列是否有可能为 NULL
190 行,tab->table()->is_nullable() 表示表中的行是否可能为 NULL,这个只会出现对外连接的内表中,如果对于外连接的外表的某一行,内表没有与之匹配的行,则内表中各字段都会用 NULL 填充,此时,表中的行就为 NULL,举个小例子:
1SELECT t3.id AS t3_id, t3.str1 AS t3_str1, t4.i1 AS t4_id, t4.str1 AS t4_str1 FROM t3 LEFT JOIN t4 ON t3.i1 = t4.i1 WHERE t3.i1 = 13744922
执行 SQL 语句得到结果如下:

上面这条外连接 SQL 中,对于 t3 表中的记录,在 t4 表中可能找不到匹配的记录,那么在执行过程中,t4 表就可能出现整行为 NULL 的情况,所以初始化 t4 表的连接缓冲区时,调用 tab->table()->is_nullable() 返回的结果为 true
如果 tab->table()->is_nullable() 的返回结果为 true,表示需要用一个标记字段来标记存入到缓冲区中的行是否有可能为 NULL
191 行,fields 加上数据字段的数量,此时 fields 里还不包含标记字面的数量
194 ~ 197 行,外连接的第一个内表,或者使用首次匹配半连接方式执行连接查询时,半连接的第一个内表,需要一个标记字段,关于该标记字段的,见 2.1 小节,对于 JOIN_CACHE_BNL::init() 主要实现功能的说明
198 行,把标记字段的数量也累加到 fields 属性中
2.3 calc_used_field_length()
2.3.1 主要实现功能
calc_used_field_length() 主要实现的功能,就是计算对于连接操作中的某个表的连接缓冲区来说,要把在它前面执行的那个表的记录存入到该连接缓冲区时,需要存入几个数据字段,存入的一行的长度是多少,具体如下:
- 要存入连接缓冲区的数据字段的数量
- 存入连接缓冲区的一行记录占用的字节数
- 存入连接缓冲区的数据字段中,blob 字段的数量
- 存入连接缓冲区的数据字段中,是否存在可能为 NULL 的字段
- 存入连接缓冲区的数据字段中,是否存在
位数不是 8 的整数倍的 BIT 类型的字段(如 status BIT(19)),为了描述方便,本文后面都把这种类型的 BIT 字段称为 未对齐 BIT 字段
位数不是 8 的整数倍,也就是没有按 8 位对齐,或者说是没有按字段对齐
2.3.2 代码分析

1050 行,这个比较重要,是 table 表需要从存储引擎返回的字段
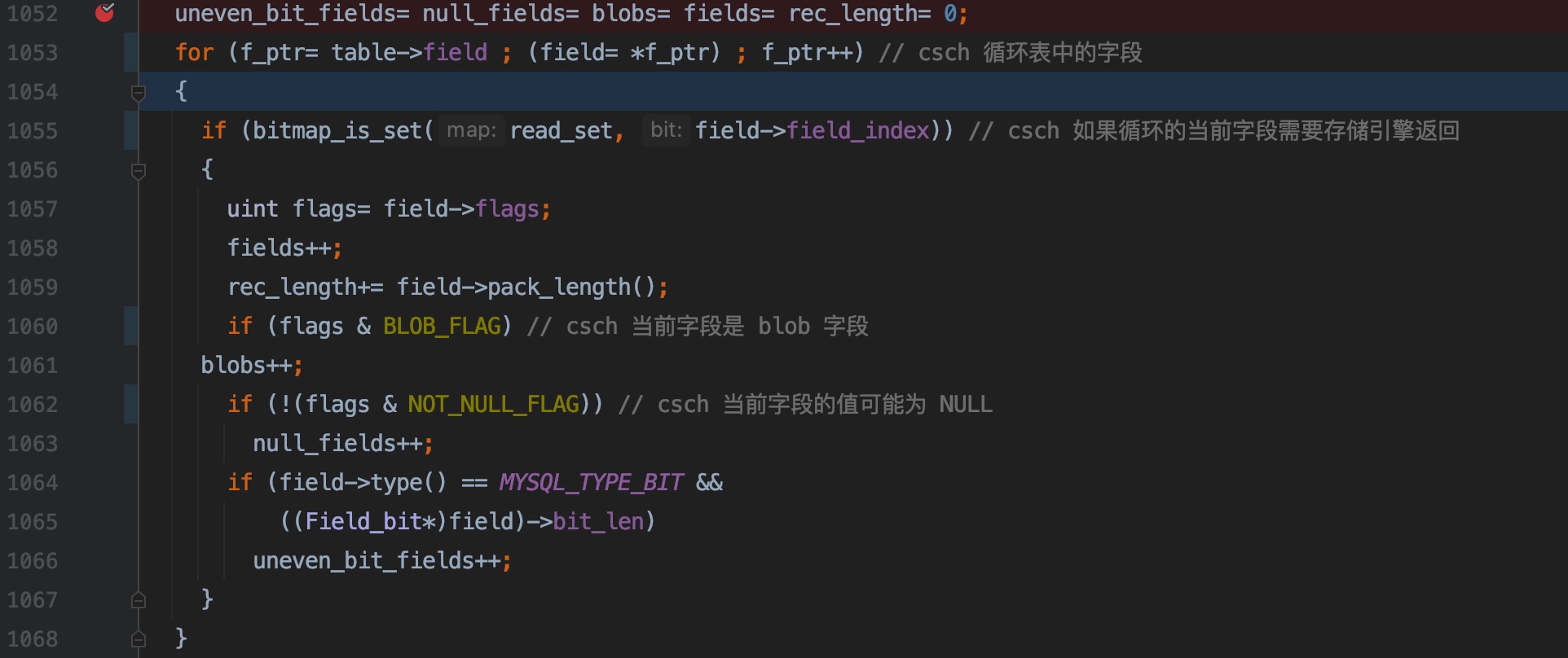
上面这段代码,循环表中的字段的,对于每个字段,进行一系列的逻辑处理
1055 行,判断从存储引擎读取记录时,当前字段会不会返回到 server 层,如果返回,才会进行一系统的逻辑处理;如果不返回,则对于该字段什么都不会干
1058 ~ 1059 行,记录字段数量、字段的长度
1060 ~ 1061 行,记录 blob 字段的数量
1062 ~ 1063 行,记录可能为 NULL 的字段的数量,实际 null_fields 字段定义为 bool 类型应该也是可以的,因为最终使用的时候,把 null_fields 赋值给了一个 bool 类型的变量,也就是说实际上不用对可能为 NULL 的字段进行计数
1064 ~ 1066 行,如果字段是 未对齐 BIT 字段,记录这种字段的数量
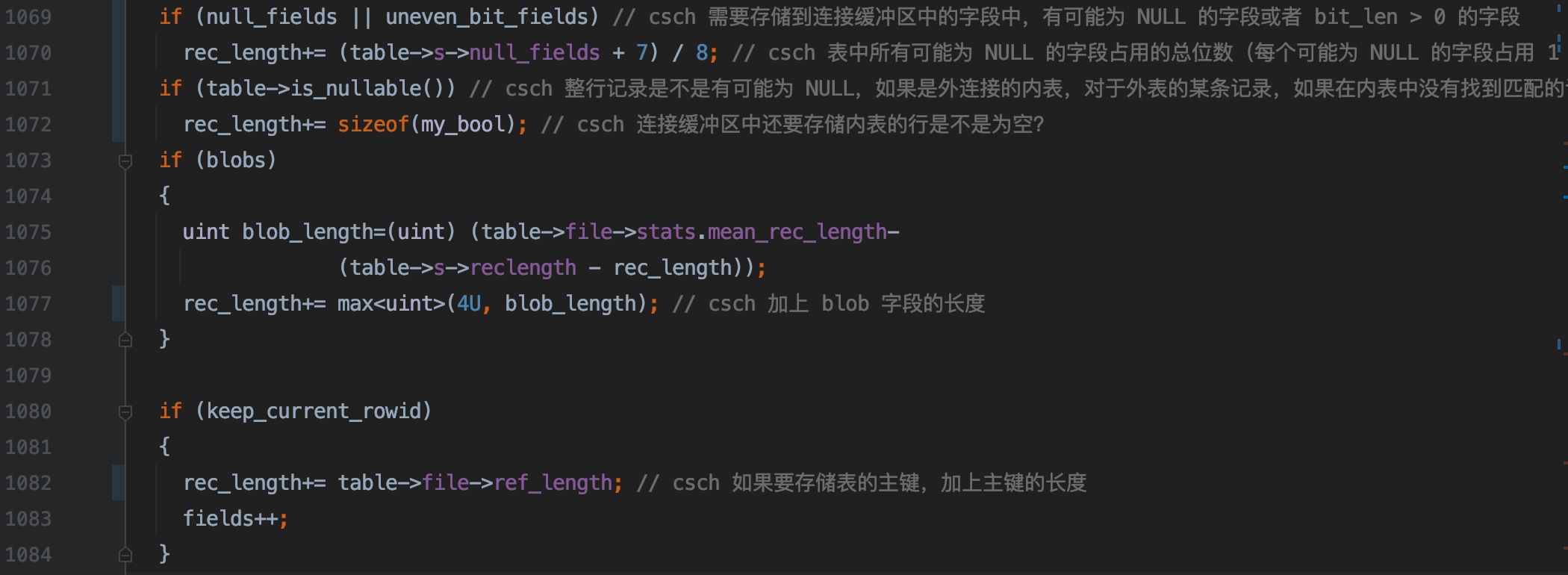
1069 ~ 1070 行,如果要加入到连接缓冲区的字段中,存在可能为 NULL 的字段,或者 未对齐 BIT 字段,存入到连接缓冲区的行长度需要加上该字段所属的表的 table->s->null_fields 按字节对齐之后占用的字节数
定义表结构时,没有带上 NOT NULL 的字段,需要用 1 位来标记该字段的值是不是为 NULL,而 table->s->null_fields 中不只包含记录字段值是不是为 NULL 的位,还包含记录 未对齐 BIT 字段 的未对齐的高位(
见 2.3.1 小节的说明) 插播一下,table->s->null_fields 中记录 未对齐 BIT 字段 的未对齐高位的代码实现在 sql/sql_table.cc 的 3819 行(null_fields+= total_uneven_bit_length)
1071 ~ 1072 行,外连接的内表,可能会存在整行都为 NULL 的情况(2.2 小节 对这种情况有过说明)
1073 ~ 1078 行,如果需要加入到缓冲区的字段中,包含有 blob 字段,那么把这些 blob 字段额外占用的长度,也要累加到 rec_length 里(这可能是为了处理 blob 字段的数据存储到溢出页的情况,暂时还没有完全搞明白是个啥)
table->file->stats.mean_rec_length 是表中行的平均长度,对应
SHOW TABLE STATUS输出结果中的Avg_row_length字段的值
1080 ~ 1084 行,如果要把行的主键也记录到缓冲区中,rec_length 加上主键的长度(1082 行),以及字段数量也需要加 1
keep_current_rowid 参数对应 QEP_TAB 对象的
keep_current_rowid属性,QEP_TAB::keep_current_rowid 是在 sql/sql_select.cc 文件 649 行赋值的(tab_in_range->keep_current_rowid= true)

1089 行,p_used_null_fields 是对 QEP_TAB::used_null_fields(该属性是个 bool 值) 的引用,所以实际上代码中 null_fields 的值只需要是 true 或 false 就行
1090 行,p_used_uneven_bit_fields 是对 QEP_TAB::used_uneven_bit_fields(该属性是个 bool 值)的引用,所以实际上代码中 uneven_bit_fields 的值只需要是 true 或者 false 就行
3. JOIN_CACHE::alloc_fields()
3.1 主要实现功能
alloc_fields() 主要实现功能是为 数据字段描述符、标记字段描述符、blob 字段描述符指针、指向前一个缓冲区的关联记录的指针 分配内存
3.2 代码分析
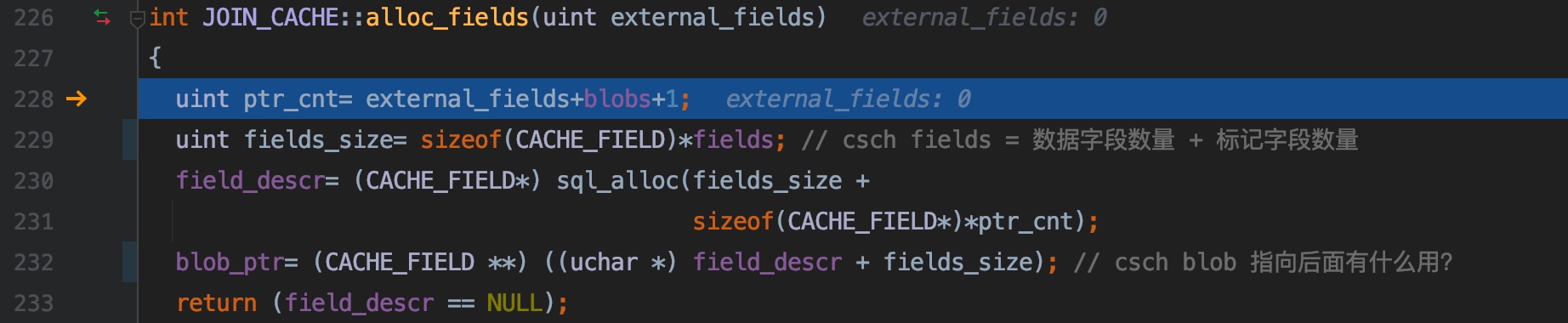
228 行,是指针的数量,BNL 缓冲区初始化时,external_fields 始终为 0,blobs 是存入到缓冲区的 blob 字段的数量,1 是什么?(嗯!还没搞明白)
230 行,为字段描述符区域(数据字段描述符、标记字段描述符分配内存),为指向 blob 数据字段描述符的指针分配内存
232 行,指向 blob 字段描述符的指针的区域在字段描述符区域之后
4. JOIN_CACHE::create_flag_fields()
4.1 主要实现功能
create_flag_fields() 方法主要功能是创建标记字段的字段描述符对象
4.2 代码分析
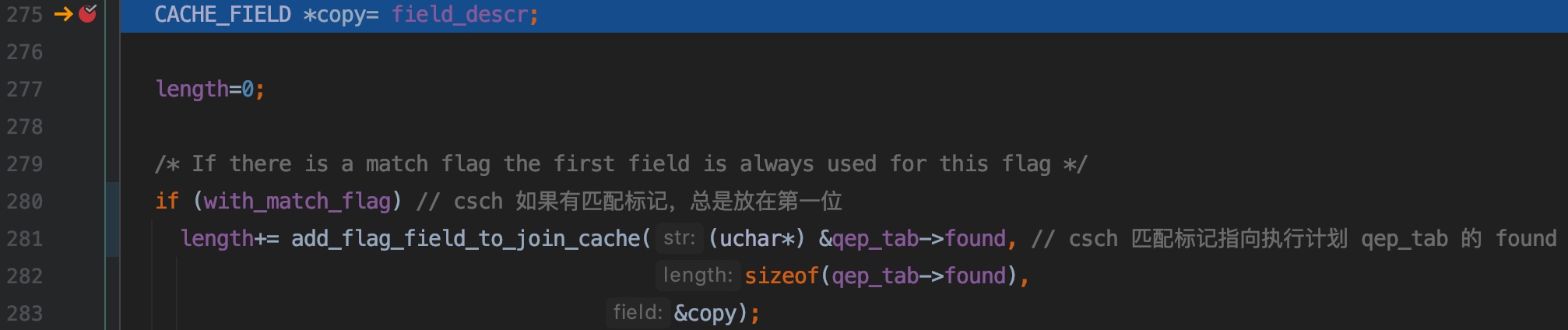
275 行,copy 指向字段描述符区域的开始
280 ~ 283 行,如果需要记录 匹配标记,则调用 add_flag_field_to_join_cache() 方法初始化匹配标记字段描述符,该字符描述符的 str 属性就指向 qep_tab->found
如果缓冲区中的行需要匹配标记,则匹配标记一定是放在行的最前面
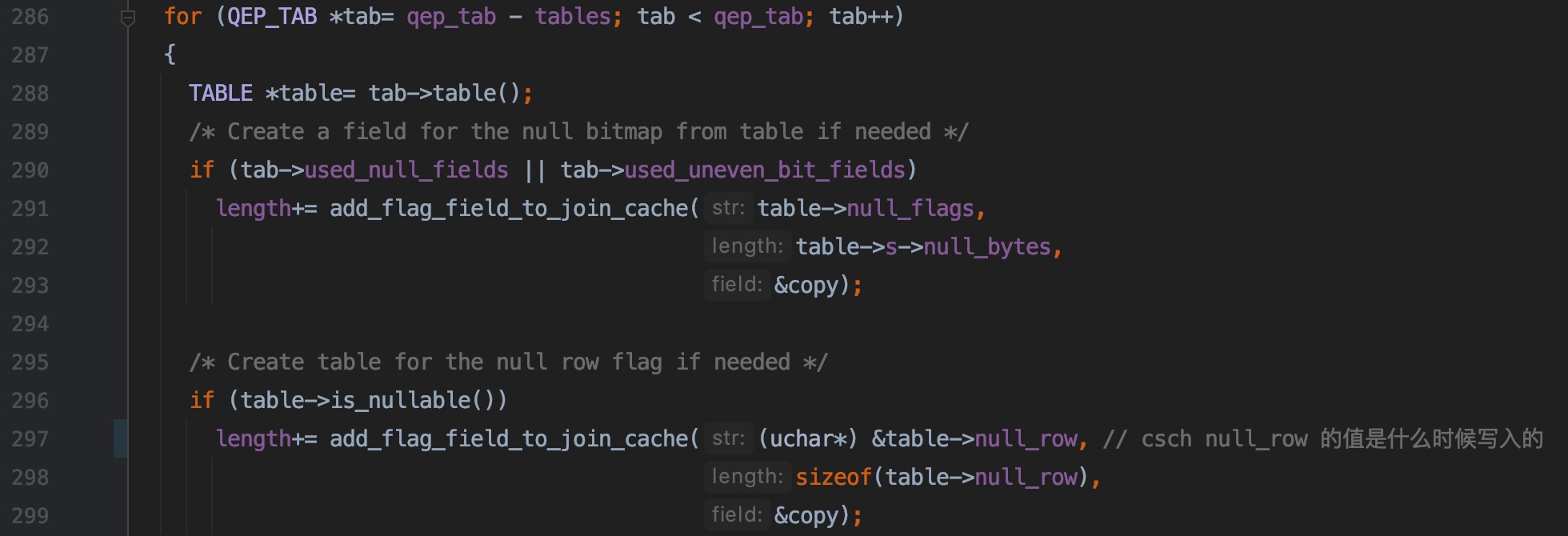
290 ~ 293 行,如果需要字段可能为 NULL 标记,则调用 add_flag_field_to_join_cache() 方法初始化该标记字段描述符,该字段描述符的 str 属性就指向 table->null_flags

296 ~ 299 行,如果需要行可能为 NULL 标记,则调用 add_flag_field_to_join_cache() 方法初始化该标记字段描述符,该字段描述符的 str 属性就指向 table->null_row

303 行,根据实际初始化的标记字段数量,再对 flag_fields 重新赋值一次(第一次赋值见 2.2 小节的代码分析)
因为 add_flag_field_to_join_cache() 里,初始化一个标记字符描述符之后,copy 指针就往后走了一个,所以 copy-field_desr 就是实际初始化的标记字段的数量
JOIN_CACHE::length 属性表示连接缓冲区中一行占用的长度,初始化标记字段之后,该属性值会增加
4.3 add_flag_field_to_join_cache()
4.3.1 主要实现功能
add_flag_field_to_join_cache() 的功能很简单,就是使用传进来的参数值,对标记字段进行初始化
4.3.2 代码分析

76 行,字段描述符的 str 属性指向相应的标记的变量
82 行,指向字段描述符的指针往后走一个,指向下一个要初始化的字段描述符结构
5. JOIN_CACHE::create_remaining_fields()
5.1 主要实现功能
create_remaining_fields() 主要是对数据字段描述符进行初始化,以及需要时,对主键字段描述符进行初始化
5.2 代码分析

调用 add_table_data_fields_to_join_cache() 对数据字段描述符进行初始化
rem_field_set 是要存入到连接缓冲区的字段,也就是需要初始化这些字段的描述符
copy 指针指向标记字段描述符之后的位置,也就是数据字符描述符的开始处
方法调用结束后:
- data_field_count 会被设置为实际初始化的数据字段描述符的数量
- copy 指向最后一个数据字段描述符的之后的位置
- data_field_ptr_count 会被设置为实际初始化指向 blob 字段描述符的指针的数量
- copy_ptr 指向最后一个 blob 字段描述符指针之后的位置
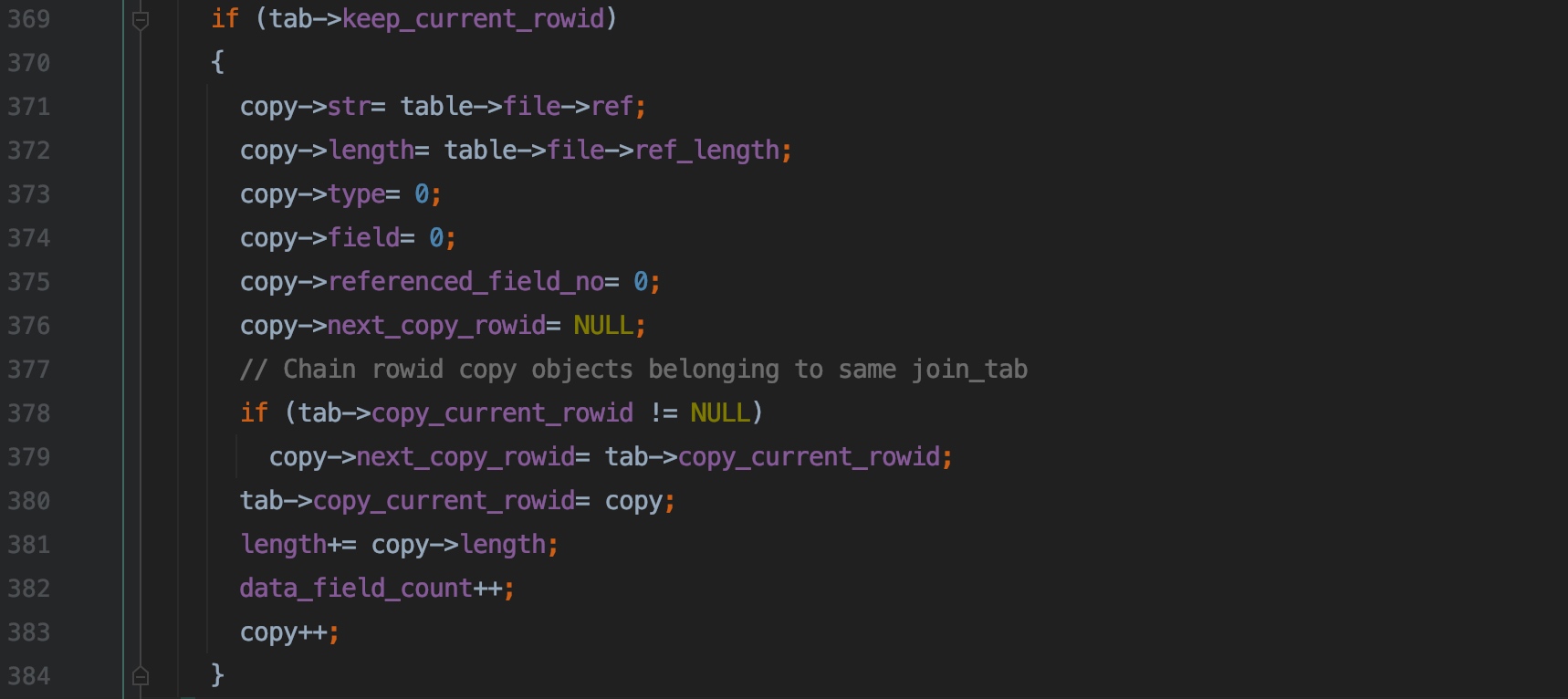
369 ~ 384 行,如果主键字段要存入连接缓冲区,初始化主键字段的字段描述符,并且数据字段描述符数量(data_field_count)的值会加 1
JOIN_CACHE::length 属性表示连接缓冲区中一行占用的长度,初始化数据字段、主键字段之后,该属性值都会增加
5.3 add_table_data_fields_to_join_cache()
5.3.1 主要实现功能
add_table_data_fields_to_join_cache() 主要功能是初始化数据字段描述符
5.3.2 代码分析
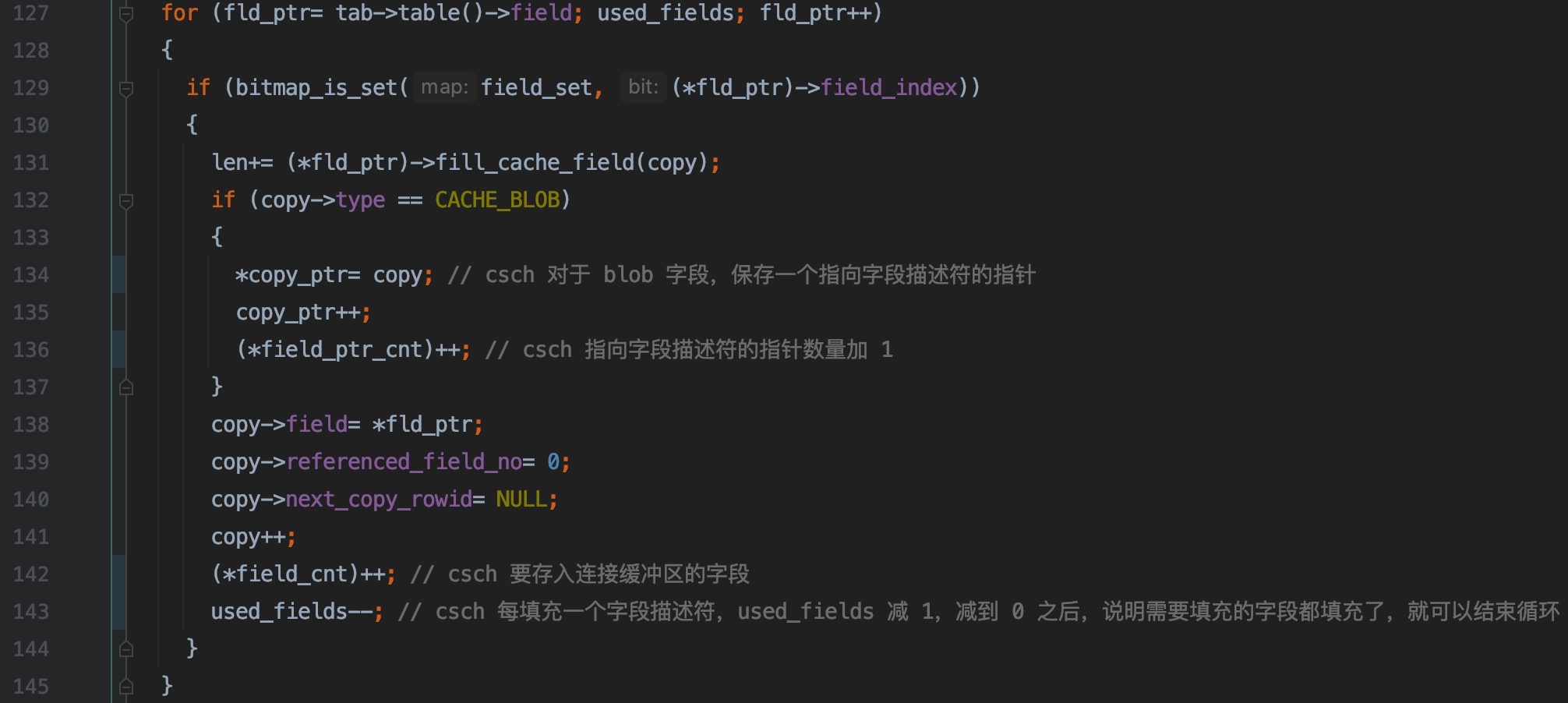
127 ~ 145 行,遍历表中的字段,为需要加入到连接缓冲区的字段初始化字段描述符
129 行,field_set 是从表中读取记录时,存储引擎层会返回给 server 层的字段,所以只有存储引擎会返回给 server 层的字段才会存入连接缓冲区(当然了,如果存储引擎不返回给 server 层的字段,字段没有数据,想存也存不了)
131 行调用 Field::fill_cache_field() 初始化字段描述符,接下来就会分析,此处先略过
132 ~ 137 行,处理 blob 字段相关逻辑,copy_ptr 为指向 blob 字段描述符的指针
5.3.3 Field::fill_cache_field()
5.3.3.1 主要实现功能
fill_cache_field() 主要功能就是初始化字段描述符对象
5.3.3.2 代码分析

2119 行,copy->str = ptr,字段描述符(CACHE_FIELD)的 str 属性指向字段(Field)的 ptr 属性,而 ptr 指向 server 层存放从引擎返回的记录的行缓冲区(record buffer)中,字段数据存储的位置的 offset,所以当从存储引擎返回一条记录时,通过 copy->str 都就以读取到 record buffer 中的字段内容了
2120 行,字段内容占用的最大字节数(多字节字符集,是定义时候指定的字符数 * 每个字符占用的最大字节数,如:utf8 字符集,content varchar(100),pack_length() = 100 * 3 = 300 字节)
2121 行,数据字段描述符还要保存个指向字段同对象的引用
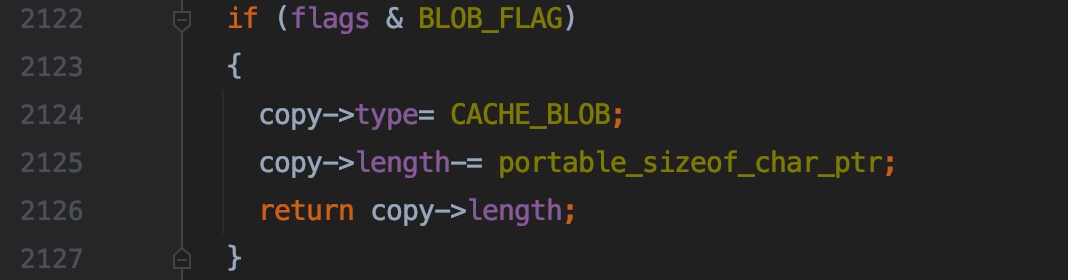
2122 ~ 2127 行,初始化 blob 字段的描述符
2124 行,表示这是一个 blob 数据字段的描述符,在后面读写连接缓冲区时,会进行一些特殊的处理,留到后面写相关文章的时候再说这部分的内容吧
2125 行,还没有搞明白为什么要这么干,后面搞明白了再补充

2128 ~ 2314 行,疑似是 char 类型的字段同,标记写入连接缓冲区时,要清除后面的空白符,同时在连接缓冲区中要用 2 字节来存储这种字段的长度
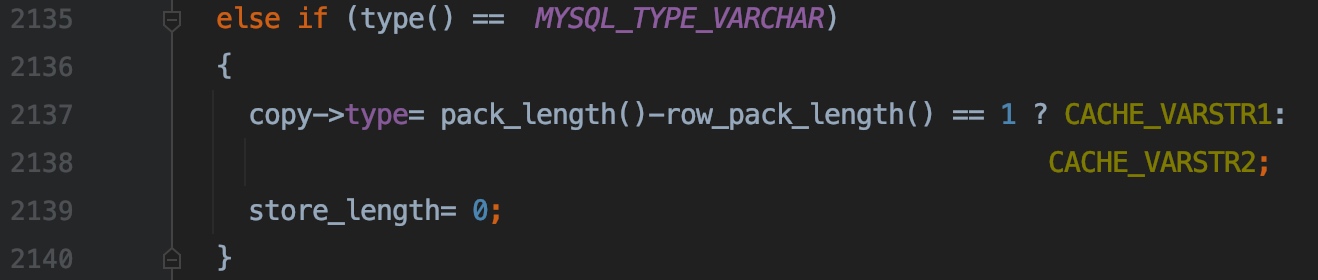
2135 ~ 2140 行,CACHE_VARSTR1 表示 varchar 字段的实际内容的长度占用 1 字节,CACHE_VARCHAR2 表示 varchar 字段的实际内容的长度占用 2 字节,因为通过类型就能知道字段的长度了,所以 store_length 设置为 0,不需要在连接缓冲区中再额外存储字段的长度了

2141 ~ 2145 行,对于除 blob 字段、char 字段、varchar 字段之外,其它字段描述符的 type 都为 0,也不需要额外空间来存储长度,所以 store_length = 0

2146 行,除 blob 字段之外,其它类型的字段,都会执行这一行,说明当前字段除了内容需要占用连接缓冲区的空间之外,内容的长度本身也要占用空间(store_length = 0 的除外)
6. JOIN_CACHE::set_constants()
6.1 主要实现功能
set_constants() 主要功能是预先计算执行连接过程中,需要使用一些数值,并把计算结果保存到 JOIN_CACHE 的相应属性中
6.2 代码分析
1// sql_join_buffer.cc JOIN_CACHE::set_constants() 427 行
2with_length= is_key_access() || with_match_flag;
这个属性看起来比较重要,源代码中对于这行赋值语句有一段很长的注释,翻译内容如下:
BKA 缓冲区中的记录之前都会存有该记录长度(后文中就叫这个长度为 record_length 吧),有了这个长度,从缓冲区中读取记录构建主键字段的值时,就不用读取主键之外的那些字段了
如果在半连接首次匹配、或者外连接内表的记录匹配标记被设置为 true 时,可以通过 record_length 来跳过该记录
如果本缓冲区记录的某些字段关联了其它缓冲区的字段,因为其它缓冲区的记录的 offset 存储在本缓冲区的记录的结尾处,通过 record_length,就可以直接跳到本缓冲区记录的结尾处,从而很容易的得到其它缓冲区记录的 offset(此处缺一张图)
不过,在执行 JOIN_CACHE::set_constants() 时,还不知道是否有字段关联了其它缓冲区中的字段,后面的执行过程中,当本缓冲区中的字段关联其它缓冲区字段时,会修改 with_length 的值
1// sql_join_buffer.cc JOIN_CACHE::set_constants() 432 ~ 438 行
2
3// 计算缓冲区中行的长度
4uint len= length + fields*sizeof(uint)+blobs*sizeof(uchar *) +
5 (prev_cache ? prev_cache->get_size_of_rec_offset() : 0) +
6 sizeof(ulong) + aux_buffer_min_size();
7
8// 至少要能够存储 2 条记录,否则使用连接缓冲区就没有意义了
9buff_size= max<size_t>(join->thd->variables.join_buff_size, 2*len);
10
11// 基于缓冲区的大小来计算存储缓冲区中记录的 offset 需要占用的字节数
12size_of_rec_ofs= offset_size(buff_size);
13
14// 存储缓冲区中的【记录的长度】需要多少字节
15// 包含 blob 字段时比较特殊了
16size_of_rec_len= blobs ? size_of_rec_ofs : offset_size(len);
17
18// 存储字段在记录中的 offset需要多少字节
19size_of_fld_ofs= size_of_rec_len;
uint len = ... 这一行计算的东西比较多,下面对每个部分做个说明:
- length:标记字段的内容长度(见
JOIN_CACHE::create_flag_fields())+ 数据字段的内容长度(见create_remaining_fields()) - fields*sizeof(uint):存储缓冲区的每个字段在行中的 Offset 占用的字节数
- blobs*sizeof(uchar *):存储 指向缓冲区的行中 blob 字段的指针的长度
- (prev_cache ? prev_cache->get_size_of_rec_offset() : 0):如果连接缓冲区关联了前一个缓冲区,此值为指向前一个缓冲区中的记录的 Offset,否则为 0
- sizeof(ulong):存储缓冲区的行的长度占用的字节数
1// sql_join_buffer.cc JOIN_CACHE::set_constants() 444 ~ 449 行
2
3// 记录长度占用字节数 + 关联其它缓冲区的记录的 offset 占用的字节数 + 数据字段、标记字段占用字节数
4// 注意:pack_length 没有包含【指向 blob 字段描述符的指针】占用的字节数
5pack_length= (with_length ? size_of_rec_len : 0) +
6 (prev_cache ? prev_cache->get_size_of_rec_offset() : 0) +
7 length;
8
9// pack_length + 【指向 blob 字段描述符的指针】占用的字节数
10pack_length_with_blob_ptrs= pack_length + blobs*sizeof(uchar *);
11
12// 以下两个种情况,check_only_first_match = true
13// 1. 半连接【首次匹配】
14// 2. 外连接的最后一个内表的 not exists 优化
15check_only_first_match= calc_check_only_first_match(qep_tab);
外连接的最后一个内表的 not exists 优化,还没搞明白是个啥,等后面再补充
7. JOIN_CACHE::alloc_buffer()
7.1 主要实现功能
alloc_buffer() 功能就很简单了,为连接缓冲区存储从表中读取的记录分配空间
7.2 代码分析
1// sql_join_buffer.cc 461 行,JOIN_CACHE::alloc_buffer()
2buff= (uchar*) my_malloc(key_memory_JOIN_CACHE,
3 buff_size, MYF(0));
buff_size 就是缓冲区的大小,是在 JOIN_CACHE::set_constants() 中计算并赋值的
8. JOIN_CACHE::reset_cache()
8.1 主要实现功能
reset_cache() 功能也非常简单,对刚刚分配的用于存储从表中读取的记录的内存空间进行个初始化
8.2 代码分析
1// sql_join_buffer.cc 1435 ~ 1447 行
2void JOIN_CACHE::reset_cache(bool for_writing)
3{
4 // 指向存储记录的内存空间的首地址
5 pos= buff;
6 curr_rec_link= 0;
7 if (for_writing)
8 {
9 // 缓冲区中记录数量,初始化为 0
10 records= 0;
11
12 // 指向最后写入缓冲区的记录的首地址,初始时指向缓冲区的首地址
13 last_rec_pos= buff;
14 aux_buff_size= 0;
15
16 // 指向下一条即将写入缓冲区的记录的位置,其实也是最后写入缓冲区的记录的结尾处
17 end_pos= pos;
18
19 // 如果连接缓冲区中的最后一条记录的 blob 字段的数据,还在 record buffer 中,而没有拷贝到连接缓冲区中,则此值设置为 1
20 last_rec_blob_data_is_in_rec_buff= 0;
21 }
22}
欢迎扫码关注公众号,我们一起学习更多 MySQL 知识:
