MySQL 不相关子查询怎么执行?
经过上一篇 where field in (...) 的开场准备,本文正式开启子查询系列,这个系列会介绍子查询的各种执行策略,计划包括以下主题:
- 不相关子查询 (Subquery)
- 相关子查询 (Dependent Subquery)
- 嵌套循环连接 (Blocked Nested Loop Join)
- 哈希连接 (Hash Join)
- 表上拉 (Table Pullout)
- 首次匹配 (First Match)
- 松散扫描 (Loose Scan)
- 重复值消除 (Duplicate Weedout)
- 子查询物化 (Materialize)
上面列表中,从表上拉(Table Pullout)开始的 5 种执行策略都用 Join 实现,所以把嵌套循环连接、哈希连接也包含在这个系列里面了。
子查询系列文章的主题,在写作过程中可能会根据情况调整,也可能会插入其它不属于这个系列的文章。
本文我们先来看看不相关子查询是怎么执行的?
本文内容基于 MySQL 8.0.29 源码。
目录 [TOC]
正文
1. 概述
从现存的子查询执行策略来看,半连接 (Semijoin) 加入之前,不相关子查询有两种执行策略:
策略 1,子查询物化,也就是把子查询的执行结果存入临时表,这个临时表叫作物化表。
explain select_type = SUBQUERY 就表示使用了物化策略执行子查询,如下:
1+----+-------------+---------+------------+-------+------------------------+----------------+---------+--------+------+----------+--------------------------+
2| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
3+----+-------------+---------+------------+-------+------------------------+----------------+---------+--------+------+----------+--------------------------+
4| 1 | PRIMARY | city | <null> | ALL | <null> | <null> | <null> | <null> | 600 | 33.33 | Using where |
5| 2 | SUBQUERY | address | <null> | range | PRIMARY,idx_fk_city_id | idx_fk_city_id | 2 | <null> | 9 | 100.0 | Using where; Using index |
6+----+-------------+---------+------------+-------+------------------------+----------------+---------+--------+------+----------+--------------------------+
策略 2,转换为相关子查询,explain select_type = DEPENDENT SUBQUERY,如下:
1+----+--------------------+---------+------------+-----------------+------------------------+---------+---------+--------+------+----------+-------------+
2| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
3+----+--------------------+---------+------------+-----------------+------------------------+---------+---------+--------+------+----------+-------------+
4| 1 | PRIMARY | city | <null> | ALL | <null> | <null> | <null> | <null> | 600 | 33.33 | Using where |
5| 2 | DEPENDENT SUBQUERY | address | <null> | unique_subquery | PRIMARY,idx_fk_city_id | PRIMARY | 2 | func | 1 | 5.0 | Using where |
6+----+--------------------+---------+------------+-----------------+------------------------+---------+---------+--------+------+----------+-------------+
本文我们要介绍的就是使用物化策略执行不相关子查询的过程,不相关子查询转换为相关子查询的执行过程,留到下一篇文章。
2. 执行流程
我们介绍的执行流程,不是整条 SQL 的完整执行流程,只会涉及到子查询相关的那些步骤。
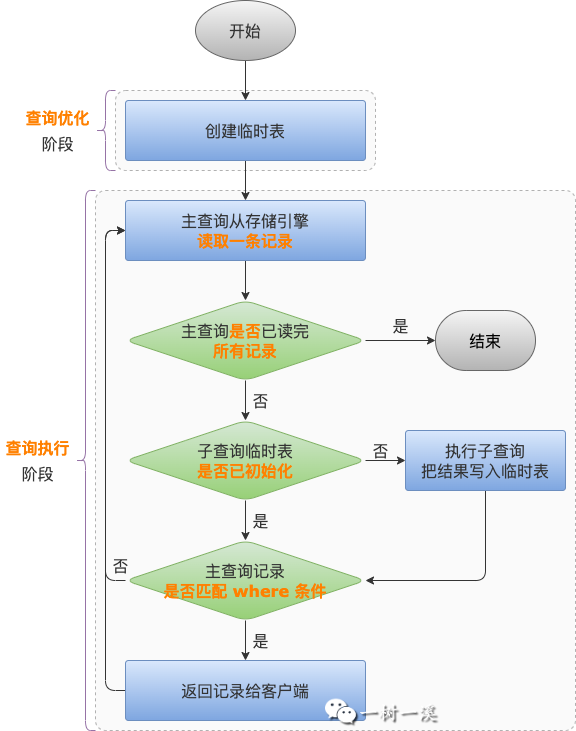
查询优化阶段,MySQL 确定了要使用物化策略执行子查询之后,就会创建临时表。
关于创建临时表的更多内容,后面有一小节单独介绍。
执行阶段,server 层从存储引擎读取到主查询的第一条记录之后,就要判断记录是否匹配 where 条件。
判断包含子查询的那个 where 条件字段时,发现子查询需要物化,就会执行子查询。
为了方便描述,我们给
包含子查询的那个 where 条件字段取个名字:sub_field,后面在需要时也会用到这个名字。
执行子查询的过程,是从存储引擎一条一条读取子查询表中的记录。每读取到一条记录,都写入临时表中。
子查询的记录都写入临时表之后,从主查询记录中拿到 sub_field 字段值,去临时表中查找,如果找到了记录,sub_field 字段条件结果为 true,否则为 false。
主查询的所有 where 条件都判断完成之后,如果每个 where 条件都成立,记录就会返回给客户端,否则继续读取下一条记录。
server 层从存储引擎读取主查询的第 2 ~ N 条记录,判断记录是否匹配 where 条件时,就可以直接用 sub_field 字段值去临时表中查询是否有相应的记录,以判断 sub_field 字段条件是否成立。
从以上内容可以见,子查询物化只会执行一次。
3. 创建临时表
临时表是在查询优化阶段创建的,它也是一个正经表。既然是正经表,那就要确定它使用什么存储引擎。
临时表会优先使用内存存储引擎,MySQL 8 有两种内存存储引擎:
- 从 5.7 继承过来的
MEMORY引擎。 - 8.0 新加入的
TempTable引擎。
有了选择就要发愁,MySQL 会选择哪个引擎?
这由我们决定,我们可以通过系统变量 internal_tmp_mem_storage_engine 告诉 MySQL 选择哪个引擎,它的可选值为 TempTable(默认值)、MEMORY。
然而,internal_tmp_mem_storage_engine 指定的引擎并不一定是最终的选择,有两种情况会导致临时表使用磁盘存储引擎 InnoDB。
这两种情况如下:
情况 1,如果我们指定了使用 MEMORY 引擎,而子查询结果中包含 BLOB 字段,临时表就只能使用 InnoDB 引擎了。
为啥?因为 MEMORY 引擎不支持 BLOB 字段。
情况 2,如果系统变量 big_tables 的值为 ON,并且子查询中没有指定 SQL_SMALL_RESULT Hint,临时表也只能使用 InnoDB 引擎。
big_tables 的默认值为 OFF。
这又为啥?
因为 big_tables = ON 是告诉 MySQL 我们要执行的所有 SQL 都包含很多记录,临时表需要使用 InnoDB 引擎。
然而,时移事迁,如果某天我们发现有一条执行频繁的 SQL,虽然要使用临时表,但是记录数量比较少,使用内存存储引擎就足够用了。
此时,我们就可以通过 Hint 告诉 MySQL 这条 SQL 的结果记录数量很少,MySQL 就能心领神会的直接使用 internal_tmp_mem_storage_engine 中指定的内存引擎了。
SQL可以这样指定 Hint:
1SELECT * FROM city WHERE country_id IN (
2 SELECT SQL_SMALL_RESULT address_id FROM address WHERE city_id < 10
3) AND city < 'China'
捋清楚了选择存储引擎的逻辑,接下来就是字段了,临时表会包含哪些字段?
这里没有复杂逻辑需要说明,临时表只会包含子查询 SELECT 子句中的字段,例如:上面的示例 SQL 中,临时表包含的字段为 address_id。
使用临时表存放子查询的结果,是为了提升整个 SQL 的执行效率。如果临时表中的记录数量很多,根据主查询字段值去临时表中查找记录的成本就会比较高。
所以,MySQL 还会为临时表中的字段创建索引,索引的作用有两个:
- 提升查询临时表的效率。
- 保证临时表中记录的唯一性,也就是说创建的索引是
唯一索引。
说完了字段,我们再来看看索引结构,这取决于临时表最终选择了哪个存储引擎:
- MEMORY、TempTable 引擎,都使用 HASH 索引。
- InnoDB 引擎,使用 BTREE 索引。
4. 自动优化
为了让 SQL 执行的更快,MySQL 在很多细节处做了优化,对包含子查询的 where 条件判断所做的优化就是其中之一。
介绍这个优化之前,我们先准备一条 SQL:
1SELECT * FROM city WHERE country_id IN (
2 SELECT address_id FROM address WHERE city_id < 10
3) AND city < 'China'
主查询 city 表中有以下记录:
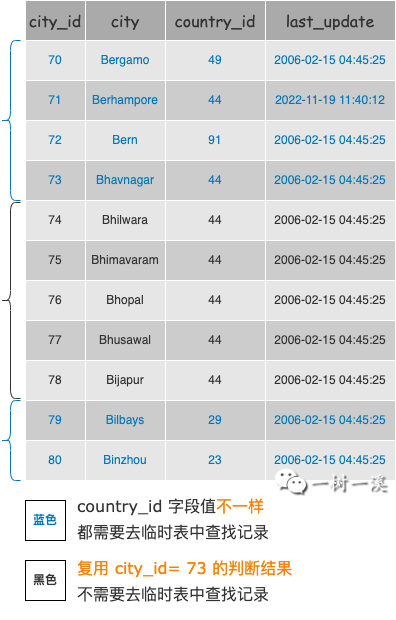
示例 SQL where 条件中,country_id 条件包含子查询,如果不对 where 条件判断做优化,从 city 表中每读取一条记录之后,先拿到 country_id 字段值,再去临时表中查找记录,以判断条件是否成立。
从上面 city 表的记录可以看到, city_id = 73 ~ 78 的记录,country_id 字段值都是 44。
从 city 表中读取到 city_id = 73 的记录之后,拿到 country_id 的值 44,去临时表中查找记录。
不管是否找到记录,都会有一个结果,为了描述方便,我们假设结果为 true。
接下来从 city 表中读取 city_id = 74 ~ 78 的记录,因为它们的 country_id 字段值都是 44,实际上没有必要再去临时表里找查找记录了,直接复用 city_id = 73 的判断结果就可以了,这样能节省几次去临时表查找记录的时间。
由上所述,总结一下 MySQL 的优化逻辑:
对于包含子查询的 where 条件字段,如果连续几条记录的字段值都相同,这组记录中,只有第一条记录会根据 where 条件字段值去临时表中查找是否有对应记录,这一组的剩余记录直接复用第一条记录的判断结果。
5. 手动优化
上一小节介绍的是 MySQL 已经做过的优化,但还有一些可以做而没有做的优化,我们写 SQL 的时候,可以自己优化,也就是手动优化。
我们还是使用前面的示例 SQL 来介绍手动优化:

主查询有两个 where 条件,那么判断 where 条件是否成立有两种执行顺序:
- 先判断 country_id 条件,如果结果为 true,再判断 city 条件。
- 先判断 city 条件,如果结果为 true,再判断 country_id 条件。
MySQL 会按照 where 条件出现的顺序判断,也就是说,我们把哪个 where 条件写在前面,MySQL 就先判断哪个。对于示例 SQL 来说,就是上面所列的第一种执行顺序。
为了更好的比较两种执行顺序的优劣,我们用量化数据来说明。
根据 country_id 字段值去子查询临时表中查找记录的成本,会高于判断 city 字段值是否小于 China 的成本,所以,假设执行一次 country_id 条件判断的成本为 5,执行一次 city 条件判断的成本为 1。
对于主查询的某一条记录,假设 country_id 条件成立,city 条件不成立,两种执行顺序成本如下:
- 先判断 country_id 条件,成本为 5,再判断 city 条件,成本为 1,总成本 5 + 1 = 6。
- 先判断 city 条件,成本为 1,因为条件不成立,不需要再判断 country_id 条件,总成本为 1。
上面所列场景,第一种执行顺序的成本高于第二种执行顺序的成本,而 MySQL 使用的是第一种执行顺序。
MySQL 没有为这种场景做优化,我们可以手动优化,写 SQL 的时候,把这种包含子查询的 where 条件放在最后,尽可能让 MySQL 少做一点无用工,从而让 SQL 可以执行的更快一点。
6. 总结
对于 where 条件包含子查询的 SQL,我们可以做一点优化,就是把这类 where 条件放在最后,让 MySQL 能够少做一点无用功,提升 SQL 执行效率。
相关文章:
欢迎扫码关注公众号,我们一起学习更多 MySQL 知识:
